











ソフトウェア開発の動的な環境では、安定性と即時性がしばしば衝突する。チームは、納品を支える構造を崩すことなく、緊急要請をワークフローに組み込むという課題に直面することが多い。この状況は特定の組織に限ったものではなく、スクラムフレームワークにおける普遍的な緊張関係である。緊急タスクが発生したとき、多くの場合、すべてを投げ出して即座に対応しようとする本能が働く。しかし、そうするとスプリント目標が乱れ、技術的負債が膨らみ、チームの燃え尽きが生じるリスクがある。
目的はすべての受信要請を拒否することではなく、構造的な視点から管理することである。明確なプロトコルを設けることで、チームは自身のリズムを保ちつつ、重要なビジネスニーズに応じられる。このガイドは、中断を効果的に扱うためのメカニズムを詳述し、プロセスの整合性を保ちつつ、市場の現実を認識した状態で運用することを可能にする。
緊急性の本質を理解する 📋
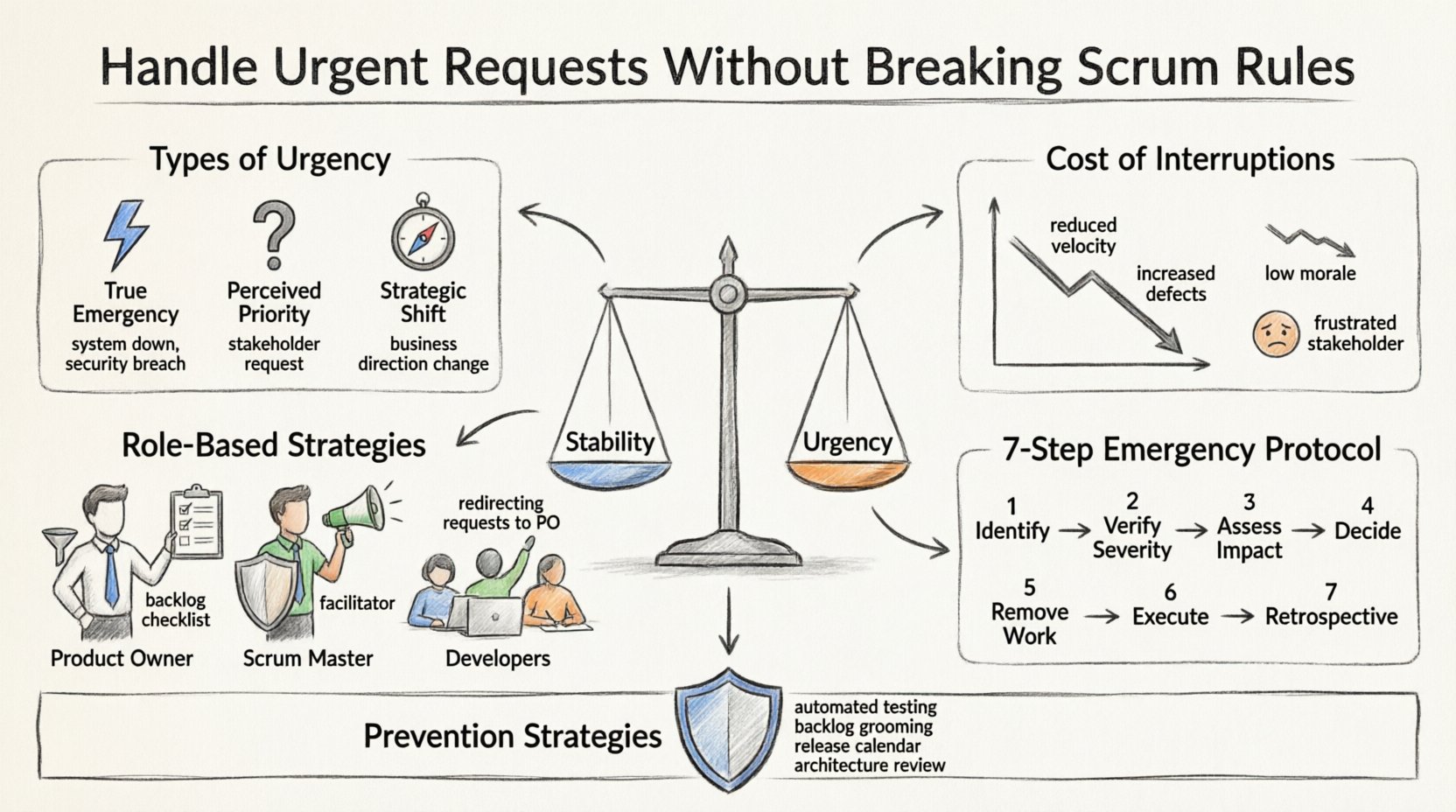
すべての緊急要請が同じものというわけではない。多くの組織では、「緊急」という状態が、現在の計画に合わないすべての項目にデフォルトで適用されるようになる。真の緊急事態と、単に優先度が高いと感じられるものとの区別が、秩序を保つ第一歩である。真の緊急事態とは、セキュリティ侵害や重大なシステム障害など、重大な被害を防ぐために即時対応が必要な状況を指す。一方、 perceived priority(認識された優先度)は、以前にニーズが満たされていなかったステークホルダーの要求から生じることが多い。
この状況を乗り越えるためには、反応性よりも集中力を重視する姿勢をチームが採らなければならない。スクラムフレームワークは、チームが価値を予測可能に提供できるように、その能力を守ることを目的として設計されている。常に焦点を変えることは、この予測可能性を損なう。チームが中断されたときのコストは、新しいタスクに費やす時間だけではなく、元の作業の文脈を再構築するのに必要な時間も含まれる。
- 真の緊急事態: システムが停止し、データが損なわれ、または顧客が製品をまったく利用できない状態。
- 認識された緊急性: ただ声に出されたことで重要に感じられる要求であり、重大な障害の基準を満たしていないもの。
- 戦略的転換: 現在のスプリント目標を無効にするビジネス方向の変更であり、臨時の挿入ではなく、正式な意思決定を要するもの。
中断のコスト 🛑
中断は生産性に測定可能な影響を与える。認知負荷に関する研究では、タスクの切り替えが著しい効率の低下をもたらす可能性があるとされている。この現象はしばしば「コンテキストスイッチング」と呼ばれる。開発者が複雑な機能の作業を中断して小さなバグや即答を要する質問に対応する場合、戻るたびにコードベースの精神的モデルを再構築しなければならない。この累積的な影響により、スピードが低下し、エラーの発生確率が高まる。
個人の生産性を超えて、チームがスプリント目標にコミットする能力が損なわれる。スプリント目標を新しい要請に合わせて放棄すれば、チームは約束を果たせない。これはステークホルダーとの信頼関係を損なう。したがって、中断を管理することは、チームを守ることだけではなく、納品プロセスの信頼性を守ることにもつながる。
管理されない中断による以下の影響を検討する:
- 速度の低下: 注意が分散するため、計画された作業に時間がかかる。
- 欠陥の増加:急いでコンテキストを切り替えることで、見落としの原因となる細部が生じる。
- チームの士気:常時火消し状態が、混沌とコントロールの欠如感を生む。
- ステークホルダーの不満: スコープクリープによる約束の不履行が、不満を生む。
役割別による要請管理戦略 🤝
緊急要請の対応には、スクラムの3つの役割間での協力が不可欠である。各役割には、緊急作業のフィルタリング、優先順位付け、実行に関する明確な責任がある。これらの境界を明確にすることで、チームはフレームワークを崩すことなく対応できる。
プロダクトオーナーの責任
プロダクトオーナーはバックログのゲートキーパーとして機能する。バックログが最も価値のある作業を反映していることを保証する責任がある。緊急要請が届いた際には、現在の計画と照らし合わせてその価値を評価しなければならない。スプリントを中断するか、次のイテレーション用にバックログに追加するかは、プロダクトオーナーの権限である。
- 受信するノイズをフィルタリングする: プロダクトオーナーは初期の要請を吸収し、明確なユーザーストーリーに変換すべきである。
- 価値を評価する:緊急リクエストが現在のスプリント目標よりもより高い価値を提供するかどうかを判断する。
- 期待を管理する:その決定が採択された場合、リクエストをすぐに取り入れられない理由を明確に伝える。
- 再優先順位付けする:緊急リクエストが承認された場合、プロダクトオーナーはスプリントの容量を維持するために、同等の作業量を削除しなければならない。
スクラムマスターの責任
スクラムマスターはプロセスを守る。チームがスクラムのルールを遵守していることを確認し、外部からの干渉を最小限に抑える。緊急リクエストが流れを妨げた場合、スクラムマスターは障害の除去を促進し、チームが不要な干渉から守られるように対応する。
- チームを守る:スプリント中にチームとステークホルダーの間のバッファとして機能する。
- 意思決定を支援する:プロダクトオーナーとステークホルダーが中断するかどうかについて合意に至るのを支援する。
- フローを監視する:中断がどれだけ頻繁に発生するかを追跡し、リトロスペクティブにそのデータを提示する。
- 境界を守る:ステークホルダーに合意されたスプリントの境界と変更の影響を思い出させる。
開発者の責任
開発者は作業を担う。彼らがタスクを実行し、集中力を守らなければならない。ビジネスに対して対応はするが、プロダクトオーナーを経由せずに直接リクエストを受け入れてはならない。
- リクエストをPOに向け直す:新しいタスクは丁寧にプロダクトオーナーに振り返し、優先順位付けを依頼する。
- 能力を監視する:品質を損なわずに追加作業をこなせるチームの能力について正直に述べる。
- 解決策を共同で検討する:緊急事態が発生した場合、最も効率的な解決経路を見つけるために協力する。
- 中断を記録する:チームのメトリクスに中断を記録し、パターンを浮き彫りにする。
緊急対応プロトコル 🚨
最良の計画を立てても、緊急事態は発生する。事前に定義されたプロトコルがあることで、チームは混乱せずに素早く対応できる。このプロトコルにより、中断を決める決定が意図的であり、チームが関係するトレードオフを理解していることが保証される。
以下の表は、スプリント内での本物の緊急事態に対処するための標準手順を概説している:
| ステップ | アクション | 責任ある役割 |
|---|---|---|
| 1 | 問題を特定する | チームメンバー |
| 2 | 深刻度を確認する | スクラムマスターとPO |
| 3 | スプリント目標への影響を評価する | プロダクトオーナー |
| 4 | スプリントを中止するか、適応するかを決定する | ステークホルダーとPO |
| 5 | 既存の作業を削除する | プロダクトオーナー |
| 6 | 緊急タスクを実行する | 開発者 |
| 7 | リトロスペクティブを更新する | 全チーム |
緊急事態がスプリントの中止を正当化するほど深刻な場合、スクラムマスターはその決定を促進しなければなりません。これは稀な出来事であり、スプリント目標がもはや達成不可能な場合にのみ発生すべきです。チームがスプリントを継続することを決定した場合、新しいタスクを対応できるように、同等の複雑さの作業を削除しなければなりません。これによりチームの能力が維持され、過剰なコミットメントを防ぐことができます。
ステークホルダーの期待を管理する 📈
ステークホルダーはしばしばスプリントを作業の柔軟な容器と見なします。いつでもどんなリクエストも挿入できると期待するかもしれません。スクラムチームの責任は、ステークホルダーにプロセスの仕組みを教育することです。透明性が鍵となります。スピードと中断のコストに関するメトリクスを共有することで、ステークホルダーは「即効対応」が予想以上に長くかかる理由を理解できるようになります。
コミュニケーションのサイクルを確立することで、この状況を管理できます。定期的なスプリントレビューにより、ステークホルダーは進捗を確認し、緊急事態になる前に懸念を表明できます。ステークホルダーが重要な問題を発見した場合は、開発者に直接連絡するのではなく、プロダクトオーナーに即座に連絡するよう促すべきです。
重要なコミュニケーション戦略には以下が含まれます:
- ビジュアルマネジメント:ボードを使用して、進行中の作業とブロッキングされている作業を可視化する。これにより、中断のコストが誰もが見える形になります。
- 容量計画: ステークホルダーに利用可能な容量を提示する。新しいリクエストが追加された場合、何が削除されているかを示す。
- フィードバックループ: チームの作業フローを妨げないよう、ステークホルダーがフィードバックを提供できるチャネルを構築する。
- 共感: ステークホルダーが抱えるプレッシャーを認めること。チームの集中を守ることが、最終的に彼らにより良い価値をもたらすことを説明する。
インシデント後のレビューと改善 🔄
緊急リクエストに対応した後も、作業は終わっていない。チームは将来類似の問題が発生しないように、何が起きたかを分析しなければならない。この分析はスプリントリトロスペクティブの際に行われる。責めを問うことが目的ではなく、プロセスの改善が目的である。
このレビューで尋ねるべき質問には以下が含まれる:
- このリクエストは本当に緊急だったのか、それとも待てたのか?
- 緊急事態によりスプリント目標が達成できなくなったか?
- チームが集中を回復するのにどのくらいの時間がかかったか?
- 緊急事態が発生するのを許したプロセス上の失敗はなかったか?
チームが緊急事態が頻発していると判断した場合、『完了』の定義を見直すか、アーキテクチャを洗練するべきである。多くの場合、緊急リクエストは技術的負債が原因である。症状を管理するよりも、根本原因に対処するほうが効果的である。
長期的な予防戦略 🛡️
プロトコルを持つことは必要だが、緊急リクエストに対処する最良の方法はその頻度を減らすことである。これには品質と計画に対する積極的なアプローチが求められる。
- 品質への投資: 自動テストと継続的インテグレーションにより、本番環境でのバグの発生確率が低下する。品質が高いと、火消し作業の数も減る。
- バックログの精査: 丁寧に整備されたバックログは、最も価値のある作業が常に準備されていることを保証する。これにより、反応型の優先順位付けの必要性が減る。
- リリース管理: 予測可能なリリーススケジュールを確立する。新しい機能がいつ利用可能になるかがわかれば、ステークホルダーが緊急変更を要求する可能性は低くなる。
- アーキテクチャの見直し: 定期的に技術的アーキテクチャを見直し、ビジネスの変化に対応できるようにする。大規模な見直しが必要ないよう保証する。
安定性と柔軟性に関する結論 🌟
スクラムは変化を管理するためのフレームワークを提供するが、変化の必要性を排除するものではない。深く集中できる安定性と、ビジネスニーズに応じる柔軟性のバランスを取ることが課題である。明確な役割の定義、緊急時のプロトコルの確立、ステークホルダーとのオープンなコミュニケーションを維持することで、チームはルールを破ることなく緊急リクエストに対応できる。
目標は、何も変化できない堅固な環境を作ることではない。むしろ、変化を意図的に管理できるレジリエントなシステムを作ることである。チームが自分の仕事にコントロール感を持っているとき、より高い品質の成果を生み出す。ステークホルダーがプロセスを理解しているとき、彼らは納品を信頼する。このバランスこそが、持続可能なアジャイル成功の基盤である。
思い出してください。スプリントは約束である。それを破ることは、無意識の反応ではなく、意識的な決定であるべきである。プロセスを尊重することで、チームは組織に与える価値を尊重していることになる。