Estimation in software development is often the source of friction between product owners and engineering teams. When a story is vague, developers cannot provide accurate effort estimates. This leads to unreliable sprint planning, missed deadlines, and team frustration. The root cause is rarely a lack of technical skill; it is usually a lack of clarity in the requirements.
To bridge this gap, user stories must be written with precision. They should provide enough context for a developer to understand the what, the why, and the boundaries of the work. This guide explores how to craft user stories that facilitate accurate estimation within a Scrum framework, without relying on external tools or hype.
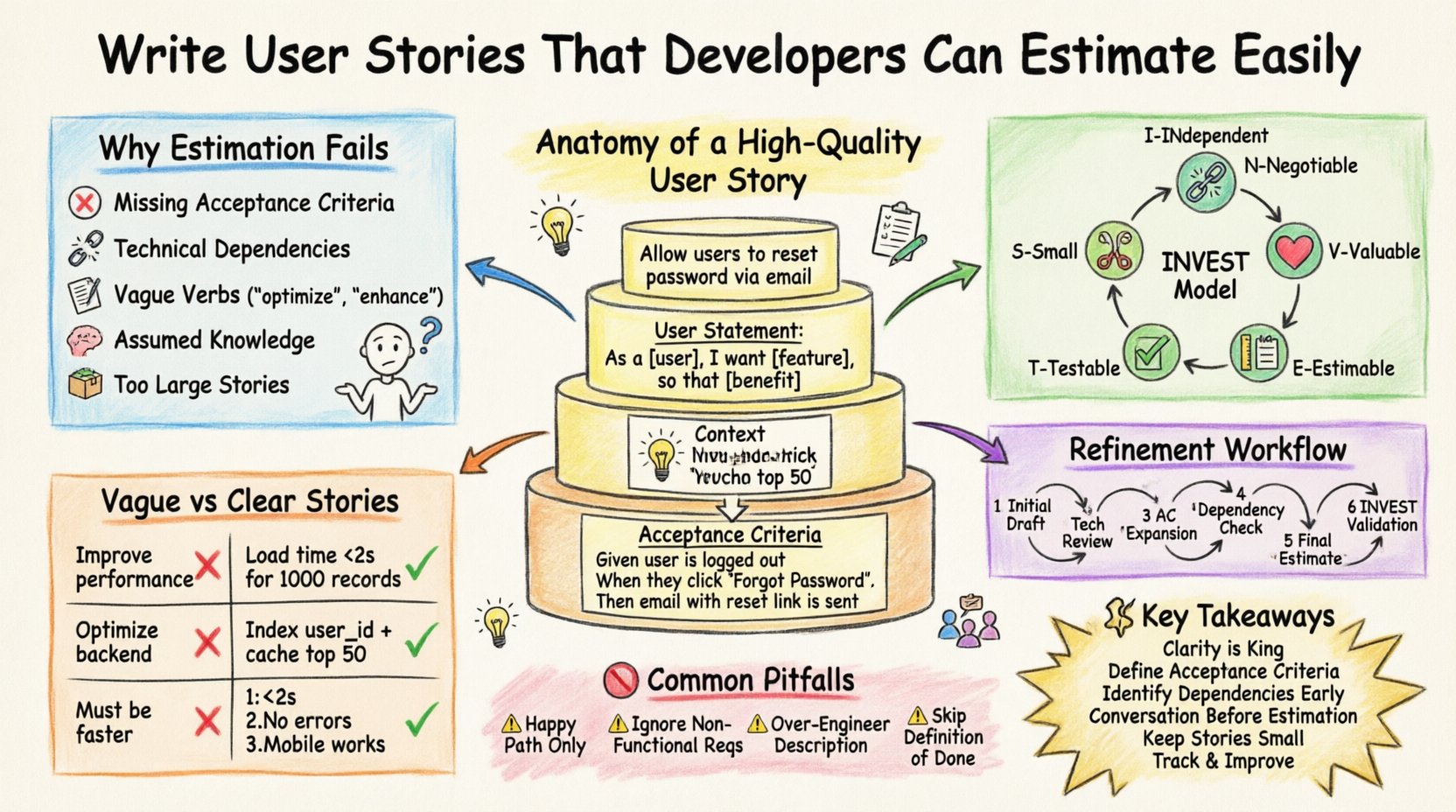
🤔 Why Estimation Fails
Developers do not estimate time; they estimate effort, complexity, and risk. When a user story is ambiguous, the unknown variables inflate the risk, which in turn inflates the estimate. Here are common reasons why stories are difficult to estimate:
- Missing Acceptance Criteria: Without clear boundaries, developers assume the worst-case scenario.
- Technical Dependencies: Stories that rely on unfinished work from other teams create uncertainty.
- Vague Verbs: Terms like “optimize,” “enhance,” or “improve” lack measurable outcomes.
- Assumed Knowledge: Relying on tribal knowledge rather than documented context.
- Too Many Stories: Large, monolithic stories that cover too much ground at once.
When a developer asks, “But how exactly does it work?”, the story is not ready for estimation. The goal is to reduce the need for clarification questions during the sprint planning phase.
📐 The INVEST Model for Estimable Stories
The INVEST model is a mnemonic used to define good user stories. While often cited, many teams overlook the Small and Testable aspects, which are critical for estimation.
1. Independent
Stories should ideally be independent. If a story relies on another story to be completed first, the team cannot estimate it in isolation. Dependencies create a blockage. If a story is truly dependent, it should be broken down until the dependency is resolved or the story is small enough to be spiked.
2. Negotiable
Stories are not contracts; they are placeholders for a conversation. However, the conversation must happen before estimation. If a story is written as a fixed specification with no room for technical discussion, it limits the developer’s ability to propose a better solution that might affect the estimate.
3. Valuable
Every story must deliver value to the end user. If a story is purely technical infrastructure with no user-facing value, it is a technical task, not a user story. Technical tasks require a different estimation approach and should be handled carefully to avoid bloating the sprint.
4. Estimable
This is the core requirement for this guide. A story is estimable if the team has enough information to determine the effort. This means:
- The user flow is clear.
- The data requirements are defined.
- The edge cases are considered.
- The performance requirements are stated (e.g., load times).
5. Small
Estimation accuracy drops as size increases. A story that takes two weeks to complete is too large. It should be split into stories that take one to three days. Small stories reduce risk and improve the granularity of the estimate.
6. Testable
If you cannot write a test for the story, you cannot define the acceptance criteria. If you cannot define the acceptance criteria, the developer cannot know when the story is done. This directly impacts estimation because “done” is the finish line.
🛠 The Anatomy of a High-Quality User Story
A user story is more than just a title. It is a package of information. To ensure developers can estimate effectively, every story should contain the following elements.
1. The Title
The title should be descriptive but concise. It should summarize the core functionality.
- Bad: Fix Login
- Good: Allow users to reset password via email link
2. The User Statement
The standard format is: “As a [role], I want [feature], so that [benefit].” This ensures the team understands the context.
3. Context and Background
Developers need to know the business context. Why is this feature being built now? Is there a regulatory requirement? Is this a fix for a critical bug? Context helps developers prioritize technical decisions.
4. Acceptance Criteria
This is the most critical section for estimation. Acceptance criteria define the boundaries of the work. They should be written in a way that allows for automated testing.
- Use Given-When-Then: This structure reduces ambiguity.
- Define Edge Cases: What happens if the internet cuts out? What if the input is empty?
- Specify Data: Are we pulling from an existing database? Are we creating new records?
📋 Comparison: Vague vs. Clear Stories
Understanding the difference between a story that causes estimation errors and one that facilitates clarity is key. The table below highlights the distinction.
| Feature | Vague Story (Hard to Estimate) | Clear Story (Easy to Estimate) |
|---|---|---|
| Goal | Improve dashboard performance. | Reduce dashboard load time to under 2 seconds for 1000 records. |
| Scope | Optimize the backend. | Index the ‘user_id’ column in the search table and cache the top 50 results. |
| Acceptance Criteria | Must be faster. | 1. Load time < 2s. 2. No errors on 1000 records. 3. Mobile view works. |
| Dependencies | None mentioned. | Requires access to the Analytics API which is currently in beta. |
🧩 Handling Dependencies and Risks
Dependencies are the enemy of estimation. If a story depends on another team’s API, the estimate is a guess. To mitigate this:
- Identify Early: Discuss dependencies during backlog refinement, not during planning.
- Create Spike Stories: If the dependency is unknown, create a story to investigate it. A spike is a time-boxed research task. It does not produce code, but it produces knowledge that reduces risk.
- Mock Data: If an external service is unavailable, agree on a mock response structure. This allows development to proceed without blocking.
- External Dependencies: If a story relies on a third-party service, note the cost and latency implications in the description.
🗣 The Role of Conversation
Writing the story is only half the job. The conversation is the other half. The written story is a reminder of the conversation, not the conversation itself.
Pre-Planning Refinement
Before sprint planning, the team should review the backlog. This is the time to ask questions. If a developer sees a gap in the story, they should flag it immediately. A story that is flagged during refinement is a story that is ready for estimation.
Clarification Questions
During refinement, specific questions should be answered. For example:
- Does this feature need to be accessible?
- Are there specific security protocols required?
- What is the maximum number of users expected?
- Do we need to support legacy browsers?
If these answers are documented in the story, the estimate becomes more reliable.
📊 Understanding Estimation Techniques
Once the story is clear, the team needs a method to estimate. The method itself matters less than the consensus it builds.
Story Points
Story points measure relative effort, complexity, and risk. They are not hours. Using story points allows teams to focus on the size of the work rather than the speed of the individual.
- Complexity: How hard is the logic?
- Risk: How likely is it to go wrong?
- Effort: How much work is involved?
Planning Poker
This is a consensus-based technique. Every developer holds up a card with a number. If the numbers vary, the highest and lowest estimators explain their reasoning. This reveals hidden assumptions. For example, one developer might have forgotten about the integration requirement, while another assumed it was already built.
🚫 Common Pitfalls to Avoid
Even with good intentions, teams often fall into traps that ruin estimation accuracy.
1. The “Happy Path” Only
Writing stories that only describe the ideal scenario is dangerous. Developers will estimate for the happy path, but the actual work includes error handling. Always include error states in the acceptance criteria.
2. Ignoring Non-Functional Requirements
Performance, security, and scalability are often overlooked. A story that says “Create a user” might take 1 point. But a story that says “Create a user that supports 10,000 concurrent logins” takes 10 points. Explicitly state non-functional requirements.
3. Over-Engineering the Description
Do not write a technical specification in the user story. The developer needs to know what to build, not how to build it. If you specify the database schema in the story, you limit the developer’s ability to choose the best solution.
4. Skipping the Definition of Done
The Definition of Done (DoD) applies to every story. It includes testing, code review, and documentation. If the DoD is not clear, the estimate will be off. Ensure the team agrees on what “done” means before estimating.
🔄 Refinement Process Workflow
To maintain a steady flow of estimable stories, follow this workflow.
- Initial Draft: Product owner writes the story with basic details.
- Technical Review: Developers review for feasibility and hidden complexity.
- Acceptance Criteria Expansion: Add edge cases and constraints.
- Dependency Check: Verify no blockers exist.
- Final Estimate: Team assigns story points during refinement or planning.
- Validation: Ensure the story meets the INVEST criteria.
📈 Measuring Estimation Accuracy
Over time, teams should track their estimation accuracy. This is not to punish individuals, but to improve the process.
- Velocity Tracking: Monitor the team’s velocity over several sprints. If velocity fluctuates wildly, the stories are likely inconsistent.
- Completion Rate: Did the team complete all the estimated stories? If not, were they blocked or underestimated?
- Re-estimation Frequency: If stories are re-estimated frequently during the sprint, the initial estimation was flawed.
🛡 Security and Compliance
For regulated industries, security and compliance are part of the estimate. A story that handles user data requires different effort than a story that displays public information. Include compliance checks in the acceptance criteria.
- Data Privacy: Does the story involve PII (Personally Identifiable Information)?
- Audit Trails: Does the system need to log who made changes?
- Encryption: Is data encrypted at rest or in transit?
If these requirements are not mentioned, the developer might build a solution that requires a major refactor later, wasting the initial estimate.
🧪 The Value of Spikes
Sometimes, a story is too risky to estimate. In these cases, use a Spike. A spike is a time-boxed investigation. It is not a deliverable feature. It is a learning task.
Example:
- Story: Investigate the feasibility of integrating with the legacy payment gateway.
- Goal: Determine if the gateway supports our required API version.
- Output: A document with findings and a recommendation.
Once the spike is done, the actual feature story can be estimated based on the findings. This reduces risk significantly.
🤝 Collaboration with QA
Quality Assurance (QA) should be involved in the refinement process. Developers might miss edge cases that testers catch. QA can help write the acceptance criteria from a testing perspective. This ensures the story is truly testable, which is a key component of estimation.
📉 Managing Scope Creep
Scope creep happens when requirements change after estimation. To prevent this:
- Freeze Criteria: Once estimated, the acceptance criteria should not change without re-estimation.
- Change Requests: If a change is needed, it must be logged and added to the backlog, not forced into the current sprint.
- Transparency: If a change is unavoidable, communicate the impact on the sprint goal immediately.
🧠 Knowledge Sharing
Estimation is a team sport. Junior developers might estimate differently than seniors. To align the team:
- Calibration Sessions: Regularly review past stories to calibrate what a “5” looks like versus a “13”.
- Pair Programming: Use pair programming for complex stories to share knowledge and reduce estimation variance.
- Documentation: Maintain a library of past stories to serve as reference points for future estimates.
🌟 Final Thoughts on Clarity
Writing user stories that developers can estimate easily is an exercise in empathy. It requires the product owner to step into the shoes of the engineer and anticipate their questions. It requires the engineer to speak up when information is missing. When both parties collaborate to remove ambiguity, estimation becomes a reliable tool for planning.
The result is not just accurate numbers. It is trust. When the team commits to a set of stories based on clear criteria, they can deliver with confidence. The focus shifts from guessing to building.
🔑 Key Takeaways
- Clarity is King: A clear story is an estimable story.
- Acceptance Criteria: Define the boundaries and edge cases explicitly.
- Dependencies: Identify and mitigate risks before planning.
- Conversation: Use refinement to discuss details before estimating.
- Small Stories: Break down large work to improve accuracy.
- Continuous Improvement: Track velocity and adjust the process over time.
By adhering to these principles, teams can transform their sprint planning from a guessing game into a structured, predictable process. The effort invested in writing good stories pays dividends in every sprint that follows.